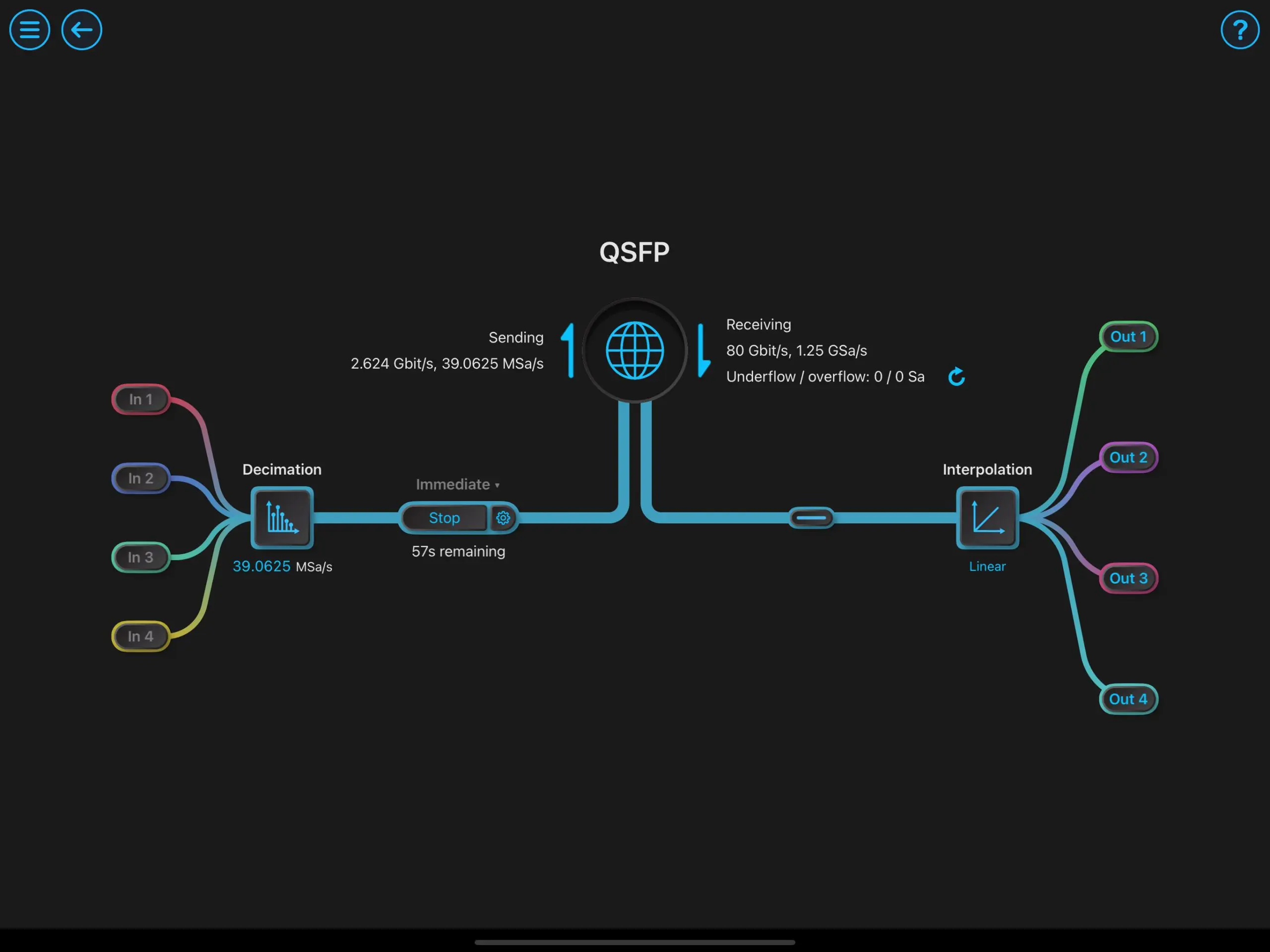
机器学习的影响力正不断扩大,涵盖科学仪器、工业自动化和实时控制等领域。然而,尽管神经网络通常与大型GPU集群和云端训练流程联系在一起,但当需要进行实时推理时,情况就截然不同了,尤其是在信号以高带宽传输且决策必须具有确定性时序的情况下。
在这些场景中,硬件的选择与模型架构同样重要。CPU、GPU 和 FPGA 各有优势,但只有一种平台能够始终如一地提供超低延迟和周期精确的确定性: FPGA.
在这篇文章中,我们比较 神经网络 本文将介绍如何在 CPU、GPU 和 FPGA 上进行推理,并解释基于 FPGA 的实现如何实现高速实时性能。模型训练在 Python 中完成,与 Moku 神经网络设备无关。训练完成后,将模型参数上传到设备,它们将在 FPGA 上运行,以进行快速、确定性的推理。

CPU:灵活易用,但并非实时型
CPU的 由于易于编程且几乎存在于所有系统中,因此仍然是小型神经网络最广泛使用的计算平台。它们提供灵活的通用计算能力,非常适合用于实验或训练小型模型。
然而,CPU难以胜任实时工作负载,因为它们缺乏深度并行性,且每次推理之间的延迟不固定。此外,CPU连接高速模拟或数字I/O的效率也有限。
GPU:吞吐量出色,但不确定
图形处理器 凭借其大规模并行架构,它们在人工智能训练领域占据主导地位。它们在加速矩阵运算和训练大型模型方面表现卓越。
但对于高速实时推理而言,GPU面临着固有的架构限制:
- 数据必须在CPU内存和GPU内存之间传输。
- GPU 针对批量处理进行了优化,而不是针对低延迟的单样本推理进行了优化。
- 它们耗电量大,需要主动冷却。
- 与传感器进行实时集成需要额外的硬件。
FPGA:专为确定性、低延迟执行而构建
FPGA 提供了一种截然不同的计算模型。它并非按顺序执行指令,而是支持完整的硬件流水线,以流式并行方式处理数据。每个神经元或层都可以映射到专用逻辑。
对于实时系统,FPGA 具有以下优势:
- 周期精确计时,其中每次推理始终需要相同数量的时钟周期。
- 超低延迟数据流通过硬件管道。
- 真正的并行是指各层同时运行,而不是顺序运行。
- 通过空间计算提高能源效率。
- 无需操作系统或驱动程序开销,即可直接与ADC、DAC和传感器I/O连接。
这些特性使得 FPGA 成为实时神经网络推理的理想平台。
为什么实时神经网络需要FPGA
实时性限制
在许多科学和工程系统中,例如实验控制、制造测试、自适应滤波以及量子或光学反馈,延迟不仅要低,而且要可预测。
FPGA 可确保纯粹的硬件时序,无需:
- 抖动
- 缓存未命中
- 不可预测的内核延迟
确定性计算与“尽力而为”计算
CPU 和 GPU 的运行遵循尽力而为的原则:性能会根据系统负载、温度或内存流量而变化。对于训练或云端推理等机器学习任务来说,这尚可接受。但对于实时控制回路而言,则远远不够。
FPGA 通过对任务逻辑进行物理结构化设计,从而实现确定性执行。这使得每次执行的延迟都完全相同。
在低功耗下实现最大吞吐量
FPGA 的空间架构允许以适中的时钟频率进行并行计算,从而实现:
- 高推理率
- 功耗低于GPU
- 稳定的热行为
- 可预测的能源消耗
这非常适合嵌入式应用和实验室仪器。
Moku如何实现神经网络推理
Liquid Instruments 的 Moku 神经网络 为科学家和工程师带来 FPGA 加速推理,而无需任何 HDL、硬件设计经验或 FPGA 工具链。 这个过程简单、快捷、易于操作。
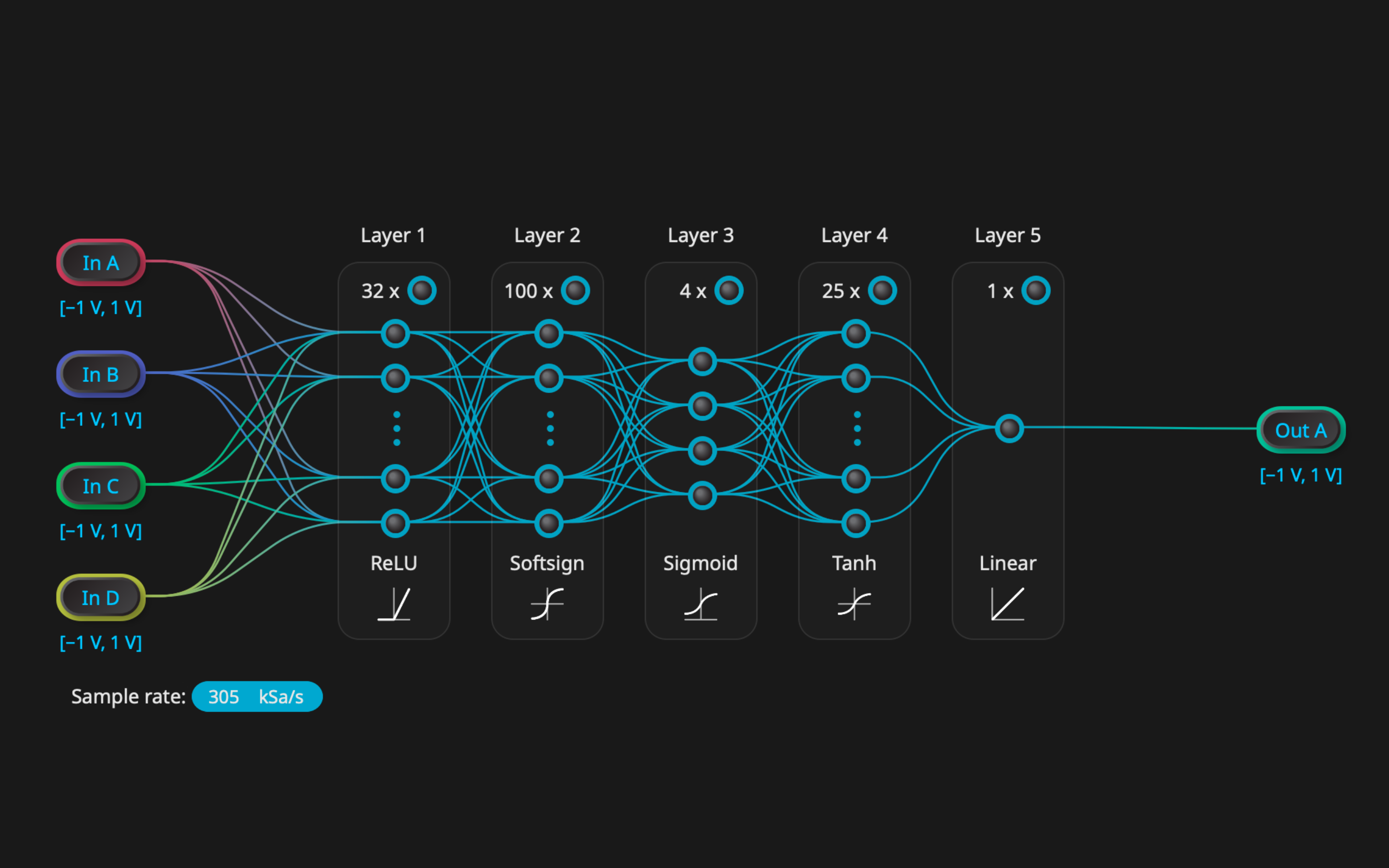
1. Python 训练
模型的设计和训练采用标准机器学习库,例如 PyTorch 或 TensorFlow。训练在离线状态下进行,可在 CPU 或 GPU 上运行。
2. 导出并转换模型
使用 Moku Python 工具,您可以将训练好的网络转换为硬件可运行的格式。这包括:
- 量化
- 图层映射
- 参数格式化
工具链在后台处理所有FPGA的具体细节。
3. 上传到 Moku
使用 API 或 GUI 将训练好的权重和网络配置上传到 Moku 仪器。
4. 基于FPGA的实时推理
部署完成后,FPGA 将神经网络作为完全流水线式的硬件电路执行,从而实现:
- 连续流推理
- 低延迟反馈
- 与 Moku 的其他仪器功能协同工作
- 确定性、实时操作
由于模型是静态的,Moku 将所有资源都用于推理,从而确保最高的可靠性和速度。
实时FPGA推理应用示例
实时实验控制
诸如光学腔锁定、干涉测量、原子传感或量子比特状态分类等应用需要微秒级(甚至更快)的决策速度。在这方面,FPGA推理的性能远超CPU和GPU系统。
制造测试和嵌入式自动化
神经网络能够对瞬态信号进行分类、检测异常情况,或以生产线速度指导自动化流程。基于FPGA的推理消除了基于PC的延迟和抖动。
高速信号处理
传统 DSP 模块可能无法满足需求,而神经网络可以近似复杂的非线性关系,同时还能以 MHz 级的采样率运行。
Moku 如何让 FPGA 推理变得轻松
传统上,基于 FPGA 的神经网络需要 HDL 编码、厂商特定的工具以及硬件专业知识。Moku 通过以下方式消除了这些障碍:
- 基于 Python 的培训到部署工作流程
- 自动量化和硬件映射
- 统一的模拟/数字 I/O 仪器生态系统
- Moku应用程序中的实时可视化和控制
- 与其他工具(如示波器、任意波形发生器、滤波器和PID控制器)无缝集成
结语
CPU 和 GPU 是优秀的训练平台,但就实时推理而言,它们的延迟、抖动和架构开销使得它们不适合高速、确定性应用。
相比之下,FPGA 具有以下优势:
- 可预测的周期精确计时
- 超低延迟
- 并行硬件执行
- 直接传感器和 I/O 集成
- 高效、连续、流式计算
Liquid Instruments 的 Moku 神经网络 Moku 将这些优势以用户友好、基于 Python 的工作流程带给科学家和工程师。通过将 FPGA 的高性能与直观的工具相结合,Moku 实现了此前大多数开发人员难以企及的新型智能实时仪器。