機械学習は、科学計測機器、産業オートメーション、そしてリアルタイム制御といった分野において、その影響力を拡大し続けています。ニューラルネットワークは大規模なGPUクラスターやクラウドトレーニングパイプラインと関連付けられることが多いですが、リアルタイム推論、特に高帯域幅で信号がストリーミングされ、決定論的なタイミングで意思決定を行う必要がある場合には、状況は大きく異なります。
このようなシナリオでは、ハードウェアの選択はモデルアーキテクチャと同じくらい重要です。CPU、GPU、FPGAはそれぞれ異なる強みを持っていますが、超低レイテンシとサイクル精度の決定論を一貫して実現できるプラットフォームは1つだけです。 FPGA.
この記事では、比較します ニューラルネットワーク CPU、GPU、FPGAにおける推論について解説し、FPGAベースの実装が高速かつリアルタイムなパフォーマンスを実現する仕組みを説明します。モデルのトレーニングは、Mokuニューラルネットワーク機器の外部でPythonで行われます。トレーニングが完了したら、モデルパラメータをデバイスにアップロードし、FPGA上で実行することで、高速かつ確定的な推論を実現します。

CPU: 柔軟でアクセスしやすいが、リアルタイムではない
CPU プログラミングが容易で、あらゆるシステムに既に導入されているため、小規模ニューラルネットワーク向けのコンピューティングプラットフォームとして最も広く利用されています。柔軟な汎用コンピューティングを提供し、小規模モデルの実験やトレーニングに最適です。
しかし、CPUは高度な並列処理能力を欠き、推論ごとにレイテンシが変動するため、リアルタイムワークロードには適していません。また、高速アナログまたはデジタルI/Oへの接続効率にも限界があります。
GPU: 優れたスループットだが決定論的ではない
GPU 超並列アーキテクチャにより、AIトレーニングの世界を席巻しています。行列演算の高速化と大規模モデルのトレーニングに優れています。
しかし、高速リアルタイム推論の場合、GPU は固有のアーキテクチャ上の制限に直面します。
- データは CPU メモリと GPU メモリ間で移動される必要があります。
- GPU は、低レイテンシの単一サンプル推論ではなく、バッチ処理用に最適化されています。
- これらはかなりの電力を消費し、積極的な冷却が必要です。
- センサーとのリアルタイム統合には追加のハードウェアが必要です。
FPGA: 決定論的かつ低レイテンシの実行向けに構築
FPGAは根本的に異なる計算モデルを提供します。命令をシーケンシャルに実行するのではなく、完全なハードウェアパイプラインを構築し、データをストリーミングかつ並列に処理します。すべてのニューロンまたは層を専用のロジックにマッピングできます。
リアルタイム システムの場合、FPGA は次の機能を提供します。
- サイクル精度のタイミングでは、各推論には常に同じ数のクロック サイクルがかかります。
- 超低レイテンシのデータはハードウェア パイプラインを介して流れます。
- レイヤーが順番にではなく同時に動作する真の並列性。
- 空間コンピューティングによる電力効率。
- OS またはドライバーのオーバーヘッドなしで、ADC、DAC、センサー I/O に直接インターフェイスします。
これらの特性により、FPGA はリアルタイム ニューラル ネットワーク推論に最適なプラットフォームになります。
リアルタイムニューラルネットワークにFPGAが必要な理由
リアルタイム制約
実験制御、製造テスト、適応フィルタリング、量子または光フィードバックなどの多くの科学および工学システムでは、レイテンシは低いだけでなく予測可能である必要があります。
FPGA は、次のようなことなしに純粋なハードウェア タイミングを保証します。
- ジッタ
- キャッシュミス
- 予測不可能なカーネル遅延
決定論 vs. 「ベストエフォート」計算
CPUとGPUはベストエフォートのタイミングで動作します。パフォーマンスはシステム負荷、温度、メモリトラフィックなどによって変動します。トレーニングやクラウド推論といった機械学習タスクでは、これは許容範囲内ですが、リアルタイム制御ループでは許容範囲外となります。
FPGAは、タスクのロジックを物理的に構造化することで、決定論的な実行を実現します。これにより、レイテンシは常に一定になります。
低消費電力でスループットを最大化
FPGA の空間アーキテクチャにより、中程度のクロックでの並列計算が可能になり、次のことが可能になります。
- 高い推論率
- GPUよりも消費電力が低い
- 安定した熱挙動
- 予測可能なエネルギー消費
これは組み込みアプリケーションやラボ機器に最適です。
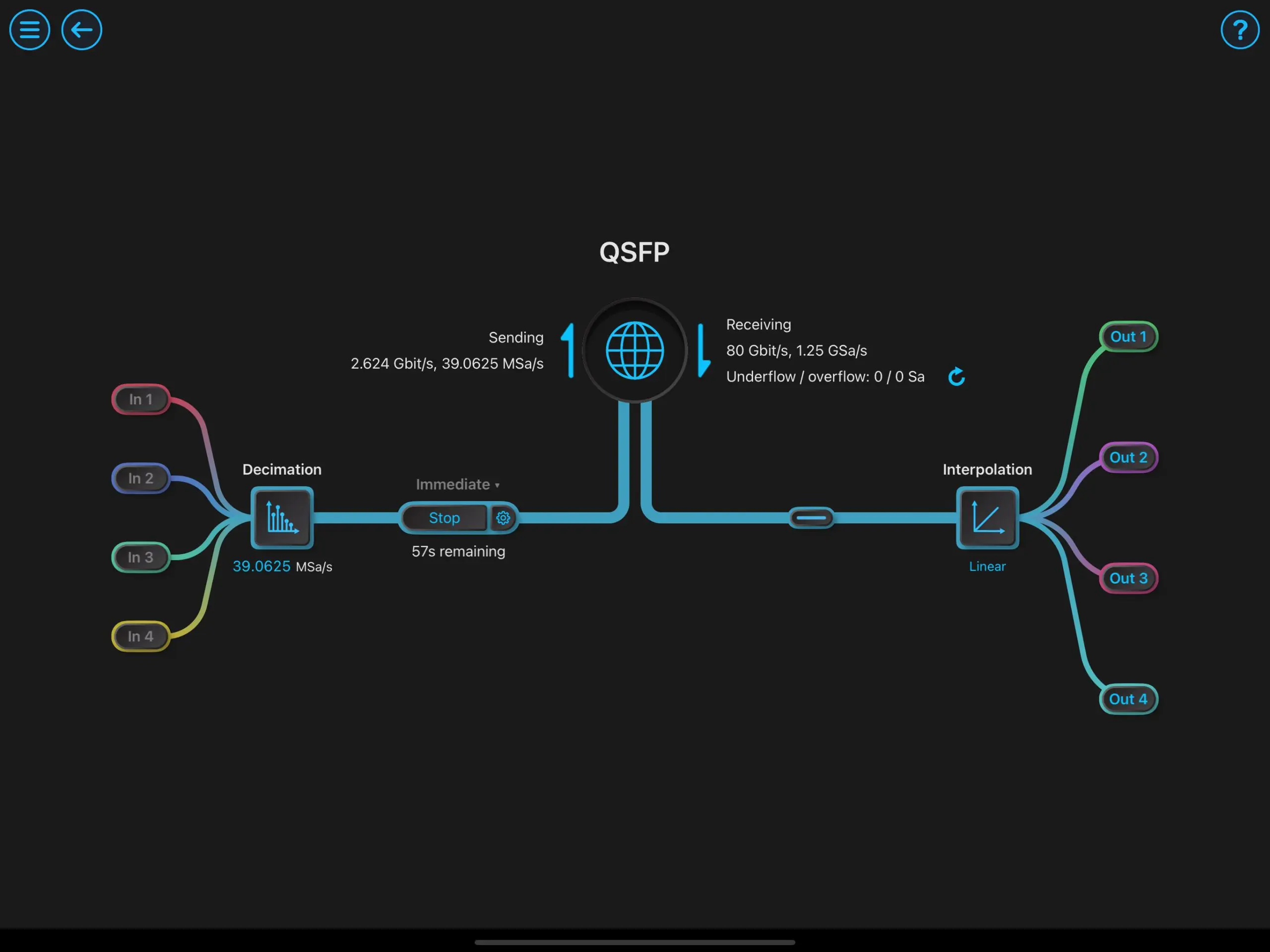
Mokuがニューラルネットワーク推論を実装する方法
リキッド・インストゥルメンツのMoku ニューラルネットワーク HDL、ハードウェア設計の経験、FPGA ツールチェーンを必要とせずに、科学者やエンジニアに FPGA アクセラレーション推論を提供します。 プロセスはシンプル、高速、そしてアクセスしやすいです。
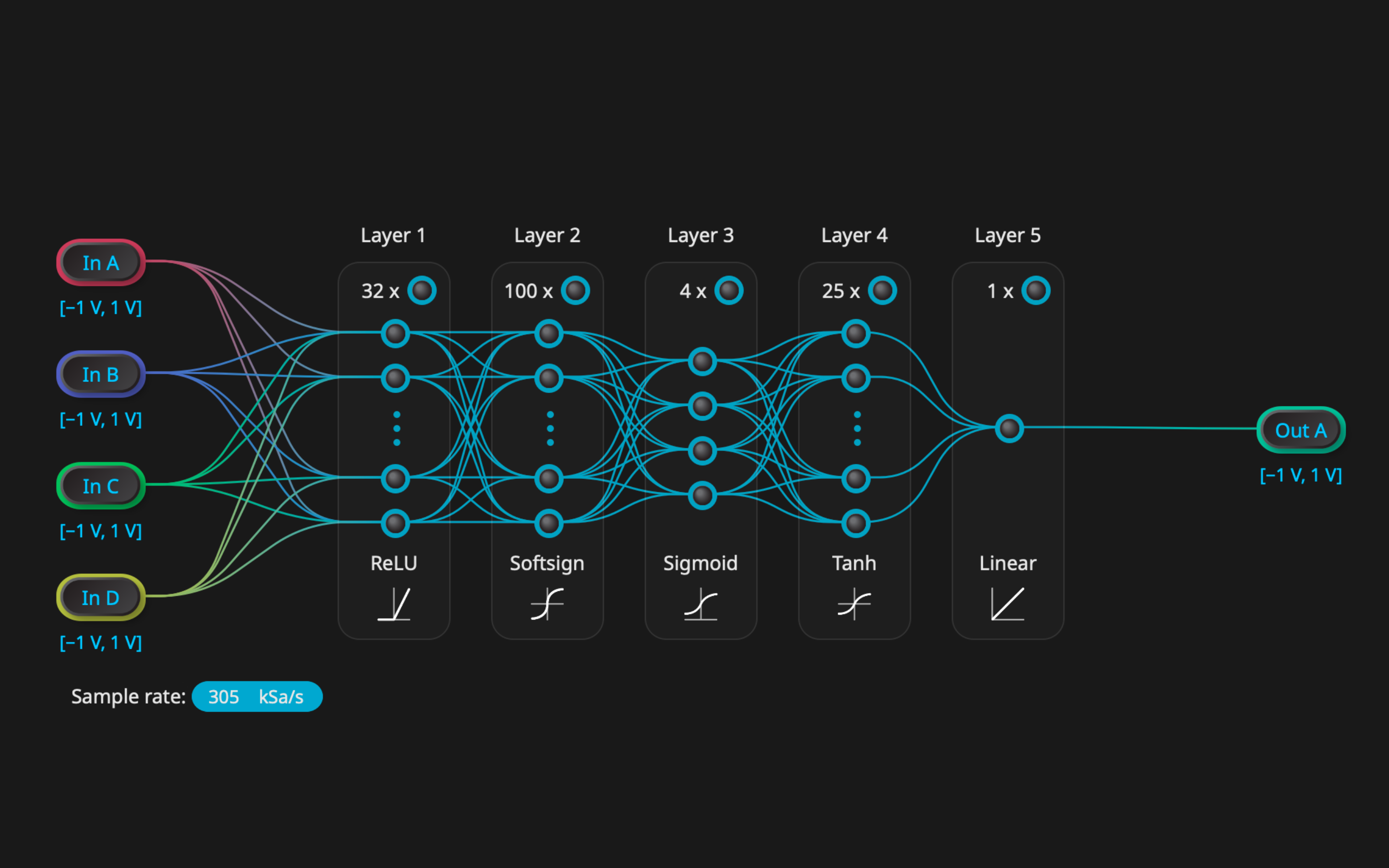
1. Pythonでトレーニングする
モデルは、PyTorchやTensorFlowなどの標準的な機械学習ライブラリを使用して設計およびトレーニングされます。トレーニングはCPUまたはGPU上でオフラインで実行されます。
2. モデルをエクスポートして変換する
Moku Pythonツールを使用すると、学習済みのネットワークをハードウェア対応形式に変換できます。これには以下のものが含まれます。
- 量子化
- レイヤーマッピング
- パラメータのフォーマット
ツールチェーンは、すべての FPGA の詳細をバックグラウンドで処理します。
3. Mokuにアップロードする
トレーニング済みの重みとネットワーク構成は、API または GUI を使用して Moku 機器にアップロードされます。
4. FPGA上でのリアルタイム推論
導入されると、FPGA はニューラル ネットワークを完全にパイプライン化されたハードウェア回路として実行し、次のことが可能になります。
- 継続的なストリーミング推論
- 低遅延フィードバック
- Mokuの他の機器との緊密な統合
- 決定論的リアルタイム操作
モデルは静的であるため、Moku はすべてのリソースを推論専用にし、最大限の信頼性と速度を保証します。
リアルタイムFPGA推論アプリケーションの例
リアルタイム実験制御
光共振器同期、干渉計、原子センシング、量子ビット状態分類といったアプリケーションでは、マイクロ秒(あるいはそれより高速)の意思決定が求められます。FPGA推論は、この点においてCPUやGPUシステムをはるかに凌駕します。
製造テストと組み込み自動化
ニューラルネットワークは、過渡現象の分類、異常の検出、ライン速度での自動プロセスのガイドなどを行うことができます。FPGAベースの推論により、PCベースのレイテンシとジッターが排除されます。
高速信号処理
従来の DSP ブロックでは不十分な場合、ニューラル ネットワークは MHz レベルのサンプル レートで実行しながら複雑な非線形関係を近似できます。
Moku が FPGA 推論を容易にする方法
従来、FPGAベースのニューラルネットワークには、HDLコーディング、ベンダー固有のツール、そしてハードウェアの専門知識が必要でした。Mokuは、以下の機能によってこれらの障壁を排除します。
- Pythonベースのトレーニングからデプロイまでのワークフロー
- 自動量子化とハードウェアマッピング
- アナログ/デジタルI/Oのための統合計測器エコシステム
- Mokuアプリでのリアルタイムの視覚化と制御
- オシロスコープ、AWG、フィルター、PID コントローラーなどの他のツールとのシームレスな統合
結論
CPU と GPU は優れたトレーニング プラットフォームですが、リアルタイム推論に関しては、レイテンシ、ジッター、アーキテクチャのオーバーヘッドにより、高速で確定的なアプリケーションには適していません。
対照的に、FPGA は次の機能を提供します。
- 予測可能なサイクル精度のタイミング
- 超低レイテンシ
- 並列ハードウェア実行
- センサーとI/Oの直接統合
- 効率的で継続的なストリーミング計算
リキッド・インストゥルメンツのMoku ニューラルネットワーク Mokuは、ユーザーフレンドリーなPythonベースのワークフローを通じて、科学者やエンジニアにこれらの利点をもたらします。FPGAの性能と直感的なツールを組み合わせることで、Mokuはこれまでほとんどの開発者にとって手の届かなかった、新たなレベルのインテリジェントなリアルタイム計測を実現します。